万能json to code 在线工具
支持各种语言
最近找json to dart的时候发现的,试了其他工具,不好用,还有bug,这个就好多了。
https://app.quicktype.io/
万能json to code 在线工具
支持各种语言
最近找json to dart的时候发现的,试了其他工具,不好用,还有bug,这个就好多了。
https://app.quicktype.io/
从Android Studio 2.3版本之后,通过Android Studio打包普遍比通过命令行调用gradle编译要快很多。这是因为Android Studio增加了一项功能。通过Android Studio打包是,检测到连接的手机android本部大于21,就会关闭传统multidex方案,而使用速度快得多的新版多dex打包流程。
google原文如下:
https://developer.android.com/studio/build/optimize-your-build
1 | // To avoid using legacy multidex when building from the command line, |
传统multidex打包流程:
1 | app:kaptGenerateStubsDevDebugKotlin |
新版多dex打包流程:
1 | :app:kaptGenerateStubsDevDebugKotlin |
可以看出,传统multidex比新版多dex打包,多了一个transformClassesWithMultidexlist的任务,而这个任务耗费时间非常的长。
这就是导致命令行调用gradle命令编译比Android Studio慢的区别。
Android Studio是通过检测连接手机的参数,来向gradle注入相关属性来修改gradle编译方式。
我们可以在build.gradle中加入如下命令来查看Android Studio注入的属性:
1 | println "projectProperties: " + project.gradle.startParameter.projectProperties |
project.gradle.startParameter.projectProperties表示当前gradle启动时设置的属性。
我测试发现,注入的属性如下:
1 | projectProperties: [ |
这几个属性:
android.injected.build.density 只打包对应density的资源,
android.injected.build.api 连接手机的android版本,就是这个属性使gradle采用新版多dex打包方案
只要在原本的编译命令中加入-Pandroid.injected.build.api=26参数,即可在命令行中也采用新版多dex打包方案
1 | ./gradlew -Pandroid.injected.build.api=26 assembleDevDebug |
我们开发中如果涉及到gradle的开发,经常需要查看各个task的输入输出。我在这里创建了一个空的android项目,然后遍历了它gradle编译时的所有task,并打印了其依赖和输入输出,方便查阅。
遍历的代码非常简单:
1 |
|
下面是运行的结果,记录在这里,方便查阅。
1 | ---------------------------------- |
tldr ! 比 man 简单好用的命令手册 使用Linux或者Mac时,经常会忘记某些命令的用法,这个时候经常就需要去百度或者谷歌搜索命令的使用说明。其实系统自带了man命令来查看手册,但是man显示的使用手册往往又臭又长,我仅仅需要临时用一个命令,为什么非要看这么长的说明书?
tldr是简化版的使用手册,并不会像man一样把所有的使用参数和说明都列出来,而是只显示常用的几个使用Sample和说明。
这是tldr tar的例子,只显示常用的7个使用方式的例子,仅有17行。 而对应的man tar 可是400多行,看使用手册都看晕了。
https://github.com/tldr-pages/tldr
tldr的安装非常简单。
Ubuntu上只要运行sudo apt install tldr即可安装成功。
Mac上运行brew install tldr即可安装成功。
其他安装方式请参考 https://tldr.sh/
What does “tldr” mean?
TL;DR stands for “Too Long; Didn’t Read”. It originates in Internet slang, where it is used to indicate that a long text (or parts of it) has been skipped as too lengthy. Read more in Wikipedia’s TL;DR article.
TL; DR代表“太长;没读”。它起源于互联网俚语,用于表示长文本(或其中的一部分)被过度冗长。阅读更多维基百科的TL; DR文章。
和tldr类似的还有bro,也是显示命令关键Sample,并且还多了快捷的提交Sample和给Sample投票的功能
http://bropages.org/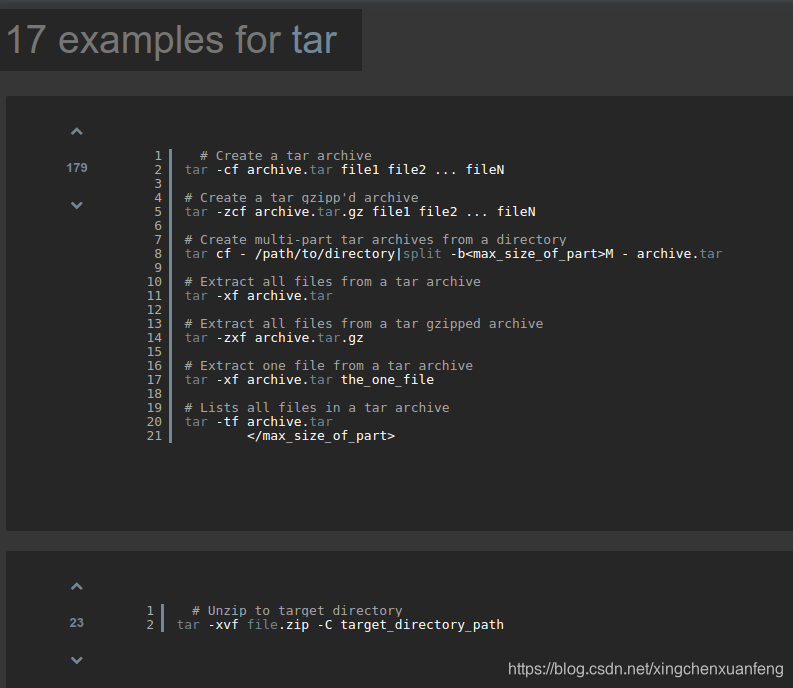
400多行的man tar手册
1 | TAR(1) tar TAR(1) |
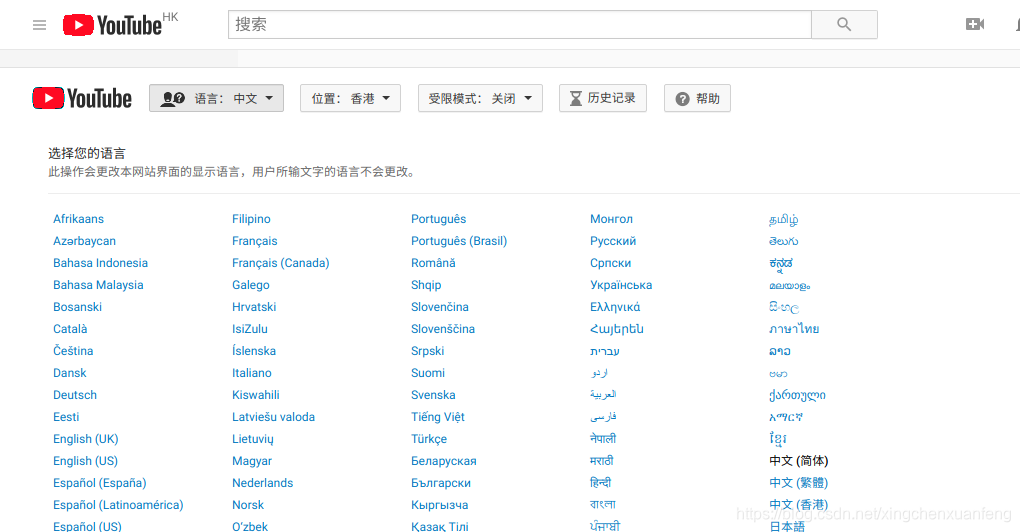
一般网站上有设置页面的,直接在设置页面里选择语言就好了,比如youtube
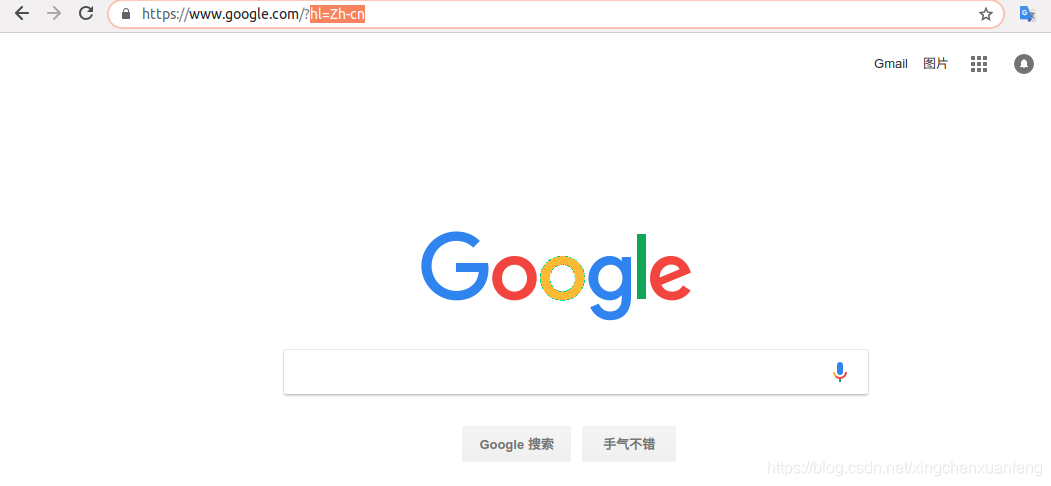
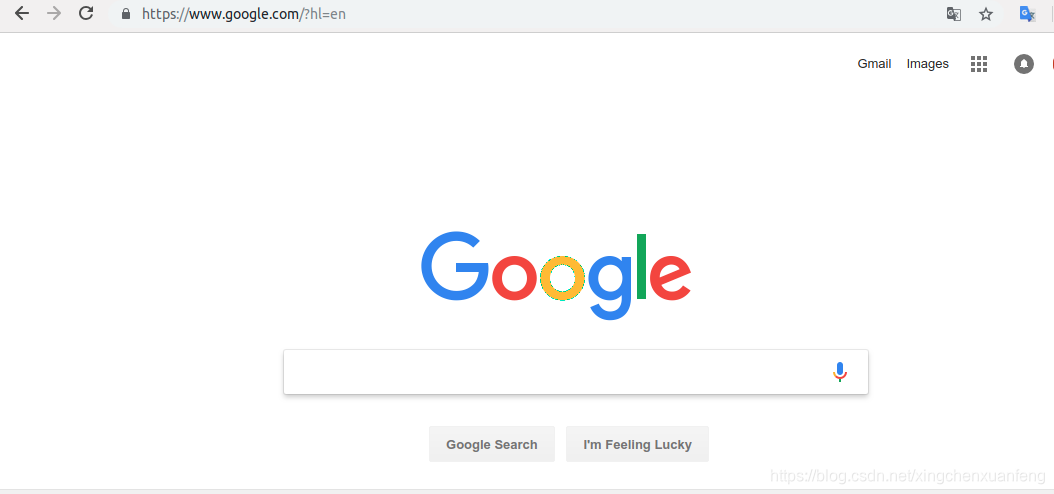
但是某些网址上没有设置页面,或者设置页面里找不到设置语言的选项,这是可以试试在链接最后面加上hl后缀,Zh-cn表示中文,en表示英文 …… 就可以切换语言了。
url?hl=Zh-cn //切换为中文
url?hl=en //切换为英文
不仅google官网如此,google系列的其他网站也是一样,比如 firebase
Firebase Crashlytics Sdk接入流程
Firebase Crashlytics是收购了Fabric而来的,服务器也是Fabric的,所以虽然Firebase中很多功能在国内是不能用的,但是 Crashlytics 这个功能却是可以用的。 大家可以放心的使用Firebase来做Crash统计分析。
考拉刚刚把crash统计平台迁移到了firebase上,在此记录一下接入Firebase Crashlytics Sdk的流程,以供大家参考。
接入一个新的SDK,最重要的文档就是官方手册,Firebase Crashlytics的官方手册是这个Firebase Crashlytics 使用入门 | Firebase,一定要注意看的是Crashlytics的文档,而不是“Firebase 崩溃报告(Firebase Crash Reporting)”,后者是firebase已经不维护的产品。
Crashlytics作为Firebase的一部分,要使用Crashlytics必须先接入Firebase。
官方文档写明的步骤本文就不再重复了,这部分的官方文档链接如下,请点击链接阅读。
将 Firebase 添加到您的 Android 项目 | Firebase
可选择使用Firebase Assistant自动配置和手动接入Firebase两种方式,推荐先尝试Firebase 智能助理自动配置,如果不能自动配置成功,再尝试手动配置。
上面按照官方文档的操作的步骤中,如果使用Firebase Assistant 要注意一定不要选“Crash Reporting”,这是firebase已经废弃的服务,然而现在新的Crashlytics却不在Assistant列表内。这一步就选Analytics就好了,不用担心选了Analytics多了冗余的依赖,使用Firebase的任何服务都要先依赖Analytics,Analytics是必需的依赖。
另外即使使用了Firebase Assistant 也建议看一遍手动添加的步骤,然后检查一下Firebase 智能助理自动生成的代码是否与手动添加的代码一致,不能完全依赖工具。
这一步完成后,当前下项目的代码情况应该是这样的:
工程级 build.gradle 文件
1 | buildscript { |
application级 build.gradle文件(通常是 app/build.gradle)
1 | apply plugin: 'com.android.application' |
google-services.json文件一定要放在application级 build.gradle(通常是 app/build.gradle)同级目录下
1 | . |
此时可以sync一遍gradle依赖,运行一下你的app,如果在应用启动时出现如下logI/FirebaseInitProvider: FirebaseApp initialization successful
则表示,app正常接入了,接下来,就该接入Crashlytics了。
如果你之前的项目使用的是Fabric Crashlytics,那你可以直接使用[Fabric迁移流程](https://fabric.io/firebase_migration)来快速迁移到Firebase Crashlytics。
否则,请继续看下面的步骤。
首先点击Firebase 控制台中的 Crashlytics按钮来开启Crashlytics服务。
然后,在项目级 build.gradle 中,添加 Crashlytics 代码库和依赖项
1 | buildscript { |
在应用级 build.gradle 中,添加 Crashlytics 相关配置
1 | apply plugin: 'com.android.application' |
做完这一步后,就可以启动app并制造一个crash,到Firebase 控制台中的 Crashlytics页面查看是否有数据上报即可。Firebase的数据上报实时性很高,尤其是新建的项目,数据量很少,出现crash后几秒钟就能在Firebase Crashlytics的平台上看到了。
建议在debug模式下添加 ext.alwaysUpdateBuildId = false标志来阻止 Crashlytics 不断更新其构建 ID,优化日常开发的编译速度。
1 | android { |
Firebase Crashlytics的官方文档只列出来了Java代码的Crash监控使用方式,并没有提及NDK Crash的监控。
对于大部分Android开发者来说,NDK的Crash也确实没有监控的必要,但是考拉这边用了很多第三方so库,这些so库也是有必要监控起来的。
Firebase Crashlytics是由Firebase收购Fabric而来的项目,技术方案也几乎没有变化,所以可以用Fabric监控NDK Crash的使用方式使用Firebase Crashlytics。
Fabric NDK Crash Reporting
1 | apply plugin: 'com.android.application' |
在manifest中声明Crashlytics手动初始化
1 | <!--手动初始化firebase Crashlytics sdk--> |
根据自身app启动流程,选择合适时机手动初始化Crashlytics
1 | Fabric.with(context, new Crashlytics(), new CrashlyticsNdk()); |
如果是本地源码编译的so而不是直接使用第三方提供的so,可以生成并上传符号表来辅助分析crash信息,执行 ./gradlew crashlyticsUploadSymbolsRelease 即可上传符号表。
以上,就完成了Crashlytics SDK NDK Crash监控的配置,可以手动引发一个Ndk Crash来测试,到统计平台上看是否有对于的Crash。
打包NDK代码引发native crash比较麻烦,在此提供一个从java代码引发NDK Crash的方式:
1 | public void crashNatively() { |
通过以上步骤的配置,现在Firebase Crashlytics已经可以正常工作了。并且还附带了发生Crash的时间,机型,系统版本,应用版本等信息以供分析。
然而实际使用过程中,我们都期望能得到更详细的用户信息,这时可以自定义添加更多数据,下面是一些考拉中添加的一些常用信息。
1 | //用户id |
这些自定义的数据可以在,Firebase Crashlytics的“键”选项卡下面看到。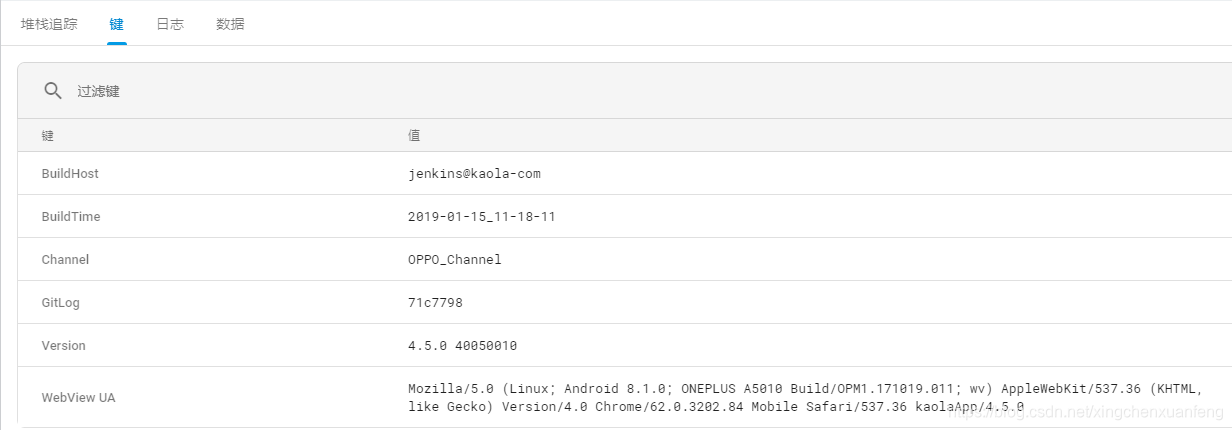
通过setUserIdentifier所设置的用户Id还可以用于搜索。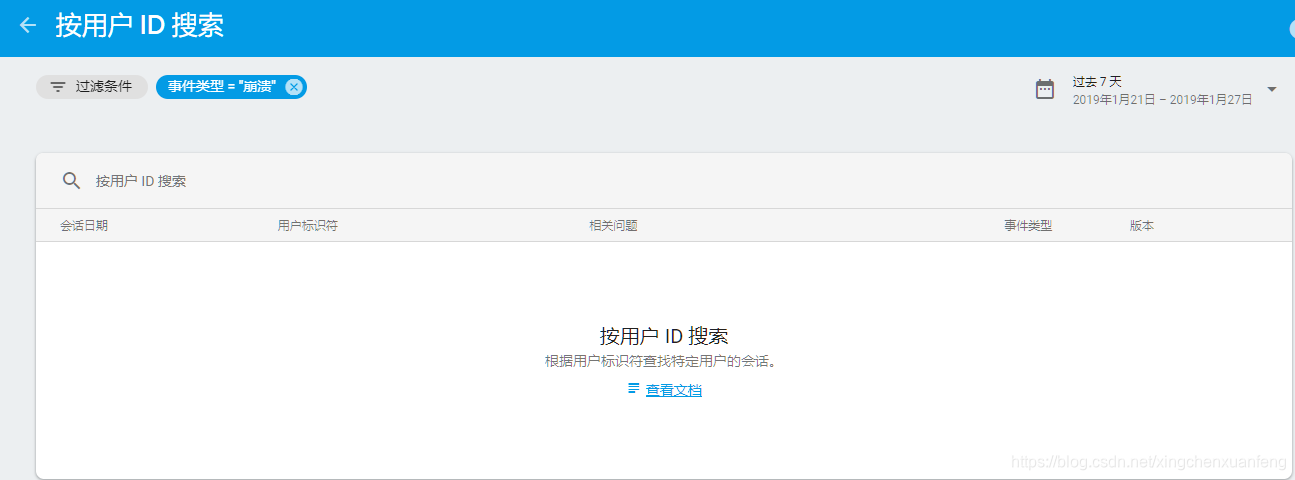
还可以通过Crashlytics.log方法,打入自定义日志用于分析。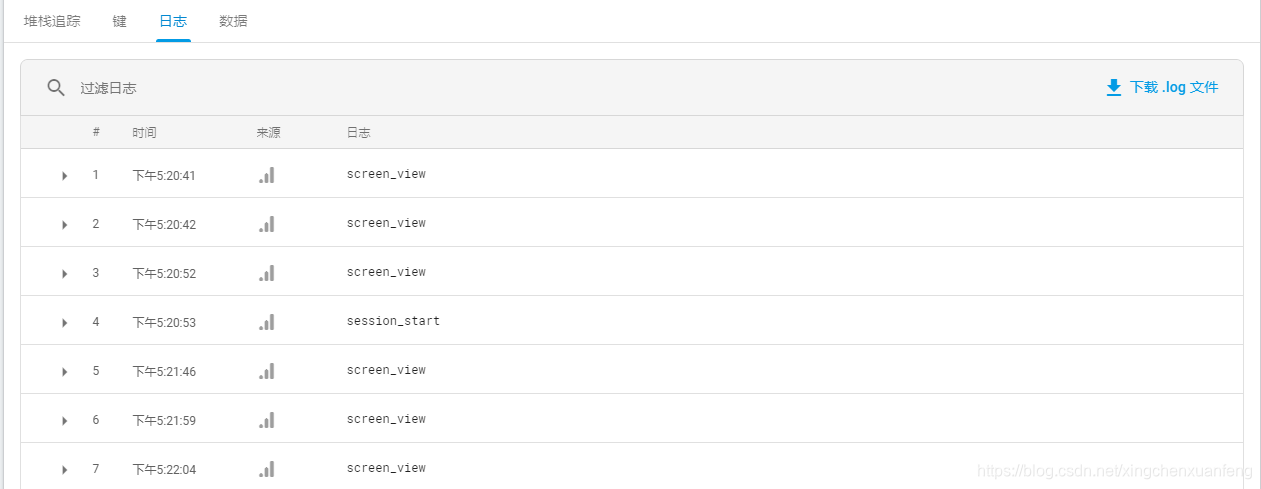
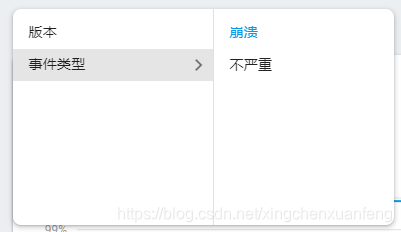
开发过程中,还会遇到通过try catch捕获了异常,不造成崩溃,但是又希望能够统计上报该异常的情况。这个时候,可以使用Crashlytics.logException(throwable)方法将异常统计上来。
在Firebase的过滤条件中选择,不严重的事件类型,即可过滤该异常。
参考官方文档 获取经过反混淆处理的崩溃报告 配置即可。
1 | -keepattributes *Annotation* |
做完以上所有步骤,基本就可以上线了。但是实际使用中发现,有用户反馈在oppo手机上会提示需要先下载谷歌服务框架才能运行。按照oppo手机的提示操作,下载好谷歌服务框架就能正常使用。
这个现象有些影响用户体验,虽然实际出现这个现象的手机是极少数(找了很多天,才在一台旧版的oppo A53m上复现了这个问题,怀疑是oppo旧版系统并且很久没有更新过才会出现),但是秉着提升用户体验的角度,还是专门做了优化。
这个弹框是这样的。
一般这种问题,只要在这种手机上,关掉crash分析即可。
然而在出现这个弹框后,app无法得到任何通知,就直接被oppo系统杀掉了,并且也找不到可靠的途径来判断是否会弹这个框。
经过一番debug加测试,基本确定,是有Activity变化的时候,会触发Firebase的统计上报功能,这时会触发com.google.android.gms.measurement.AppMeasurementReceiver这个Receiver,然后触发com.google.android.gms.measurement.AppMeasurementService这个service,然后调用gms上传数据到服务器。国内手机一般都没有gms框架,正常情况下这里发现没有gms的时候,就会走Firebase SDK内置的应用内上传逻辑。但是oppo手机比较奇怪,它应该是内置了gms上传事件的接收器,然而这个接收器的作用,不是上传数据,而是把app进程杀死,然后弹个窗(我也是醉了)。
看起来app是无法对这个现象做任何处理了,即使是通过机型来做黑名单,都不能很好的判断,毕竟即使是同一个机型,也仅有极少数会出现这个弹框,存在很大的误伤概率。
这种情况下,只剩下了一种办法,先让这个现象出现,然后下次启动时再通过上次是否出现了这个现象,来规避问题。虽然会至少出现一次不友好现象,但至少比用户一直不下载谷歌服务框架就一直出现弹窗要好一些。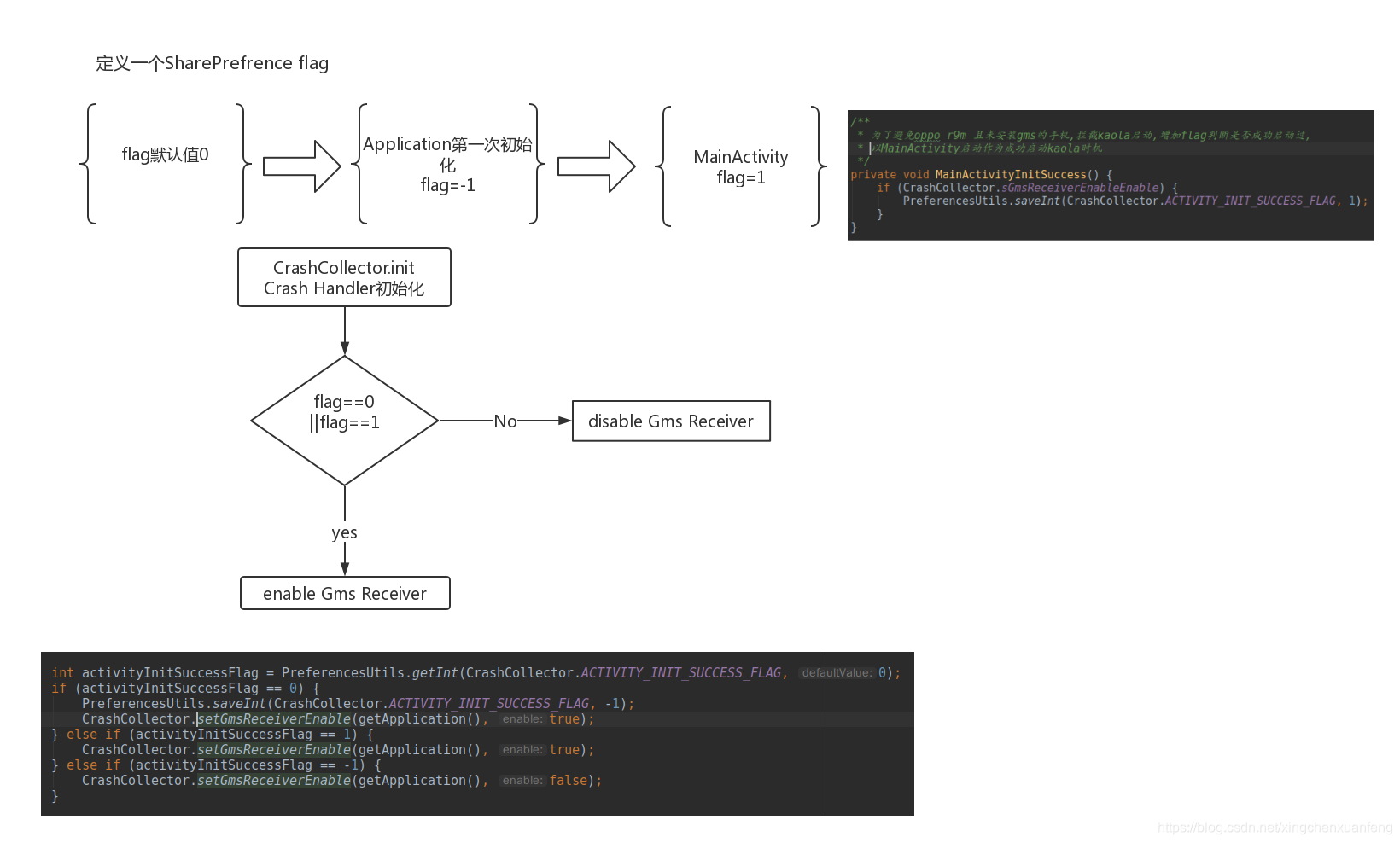
新建了一个Int类型SharePreference值,默认是0,当app第一次启动的时候,设为-1,MainActivity启动成功后,设为1。
这样,下次启动时,如果发现没有这个SharePreference值为-1,则表示上次没有成功启动,就关闭Firebase。
这里的关闭还有些特殊,直接不初始化Firebase的话,会完全失去Crash监控效果,我们只把AppMeasurementReceiver这个Receiver diasble,这样只是失去了用户信息上报,少了些log和轻微影响数据百分比准确度,不影响正常crash上报功能,最大程度保留了功能完整性。
1 | int activityInitSuccessFlag = PreferencesUtils.getInt(CrashCollector.ACTIVITY_INIT_SUCCESS_FLAG, 0); |
1 | private void MainActivityInitSuccess() { |
1 | public static void setGmsReceiverEnable(Context context, boolean enable) { |
引用:
转自:http://balistardut.github.io/2016/01/30/Linux%E7%A3%81%E7%9B%98%E7%9B%B8%E5%85%B3-%E5%88%86%E5%8C%BA%E4%B8%8E%E4%BF%AE%E5%A4%8D/
Jan 30, 2016 in linux
移动硬盘分配空间如下(其中sdb1,sdb3,sdb4为主分区,sdb5、6、7为逻辑分区):sdb 8:16 0 465.7G 0 disk
├─sdb1 8:17 0 18.7G 0 part /
├─sdb2 8:18 0 1K 0 part
├─sdb3 8:19 0 78G 0 part /media/james/My Documentes
├─sdb4 8:20 0 319.2G 0 part /media/james/UUI
├─sdb5 8:21 0 10.9G 0 part
├─sdb6 8:22 0 7.8G 0 part /media/james/mint
└─sdb7 8:23 0 31.2G 0 part /media/james/home
原来sdb5挂载在Ubuntu15.04的根目录/下,sdb6挂载在目录/usr/share下(因为该目录占用空间大,不得已将数据复制出来覆盖了原来的mint,运行时挂载,这是一个不错的扩容方法),sdb7挂载在/home下(空间最大,但是由于安装软件多,大部分都在/usr下)。问题出现在,将Ubuntu安装在3个分区上后,还是经常出现开机iNode错误,不得已必须强制关机,重启后无法进入图形界面,而进入了emergency mode的命令行界面,输入密码可正常登陆,跳过则进入Ubuntu原本的图形界面,自己安装的软件全部没有,怀疑home目录没挂载上,进入sdb1分区的deepin系统,发现sdb5无法挂载,显示不能识别的文件系统。
尝试win下修复,但都无法挂载sdb5,分区表肯定损坏了,最后又把MBR给整坏了,硬盘已经完全无法启动操作系统了。无奈最后在sdb1上新安装了mintKDE系统,才修复了MBR。期间尝试了多个网友的办法,增加了不少技能。
lsblk能列出当前系统存在的硬盘和硬盘分区情况,如下。sdb 8:16 0 465.7G 0 disk
├─sdb1 8:17 0 18.7G 0 part /
├─sdb2 8:18 0 1K 0 part
├─sdb3 8:19 0 78G 0 part /media/james/My Documentes
├─sdb4 8:20 0 319.2G 0 part /media/james/UUI
├─sdb5 8:21 0 10.9G 0 part
├─sdb6 8:22 0 7.8G 0 part /media/james/mint
└─sdb7 8:23 0 31.2G 0 part /media/james/home
我总是能看到sdb5分区,但是无法挂载。
df 能列出硬盘分区挂载情况及使用情况,掌握磁盘是否占满。james@james-ThinkPad-T440p:~ > df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sdb1 19G 4.6G 13G 27% /
/dev/sdb7 31G 3.5G 26G 12% /media/james/home
/dev/sdb6 7.6G 3.6G 3.7G 50% /media/james/mint
/dev/sda1 101G 45G 56G 45% /media/james/系统
/dev/sdb3 78G 74G 4.4G 95% /media/james/My Documentes
/dev/sdb4 320G 312G 7.5G 98% /media/james/UU
fdisk能为空磁盘分区,并且能修复partition order的错误,以前由于系统频繁装卸,存在这个错误,这个修复后,一直出现inode错误。fdisk还能列出分区的开始与结束柱头。
常用用法:fdisk /dev/sda //进入交互模式对磁盘进行操作
parted也是一个命令行分区工具。可以修改分区参数,还有一个找回丢失分区表的功能。但是我没有通过这个命令找到丢失的sdb5的分区表
参考:parted命令详解
linux的parted手册
(1)MBR:”Master Boot Record”主引导记录,BIOS检测到一个硬盘后,将磁盘的0 cylinder(0柱面),0 head(0磁头),1 sector(1扇区)的内容经过简单判断后,加载到内存中指定位置,然后跳转至该位置运行。MBR大小为512bytes,其中主要存放引导程序和该硬盘的分区表。
(2)GRUB:”GRand Unified Bootloader”:多重操作系统启动管理器,通过运行GRUB来引导进入操作系统。
(3)启动过程为:首先启动到BIOS,然后检测硬盘的MBR,将MBR该扇区的内容(也就是写在上面的GRUB)装入内存运行,再通过GRUB来引导操作系统。
(4)grub2分为2部分,一部分在MBR上,一部分在操作系统的/boot/grub下。如果进入引导界面,没有发现启动选项,而只有grub rescue,则可以通过交互找到另外一部分进行启动。操作流程如下: Ubuntu——grub rescue 主引导修复
参考:从失败的 Linux 引导中恢复
我的情况是grub rescue都被搞的无法显示了,只能通过其他方法来做。
grub-install可以将grub写入到磁盘的MBR中,但是我没有尝试成功,报错说:path ‘/boot/grub’ is not readable by GRUB on boot ,Installation is impossible 问题
然后看国外网友说Boot-Repair可以修复。
参考:GRUB配置的安装和写入硬盘的MBR
Linux中安装GRUB的两种方式
Boot-Repair是Ubuntu下一款修复启动项的图形工具,需要增加ppa,通过网络安装,由于无法成功添加ppa,没能尝试成功。后面看可以下载镜像安装。
参考:Boot Repair-能一键修复ubuntu启动/引导项的软件
easyBCD是windows下一款修复启动项工具,尝试了一下,可以成功制作windows与linux双启动项,但是由于sdb5始终无法识别挂载,且它制作的启动项不是想要的grub2。
bootice也是win下的修复启动项工具,但局限于修复windows的开机启动,没找到grub2的启动修复选项,win下的修复做的很好。
e2fsck能检查坏轨,并能自动修复磁盘错误,检查时不能挂载磁盘。使用e2fsck -a /dev/sdb5可以检查磁盘错误并自动修复。
参考:Linux磁盘修复e2fsck命令
fsck也是磁盘修改命令,检查时也不能挂载磁盘。使用fsck.ext4 /dev/sdb5可以检查磁盘错误并自动修复。运行这条命令后,出现很多问题,确认后修复。再尝试挂载sdb5,成功挂载,并且能显示分区里的文件。
参考:修复被破坏了的linux文件系统分区表
首先安装fcitx
一、检测是否安装fcitx
首先检测是否有fcitx,因为搜狗拼音依赖fcitx
> fcitx
提示:
程序“fcitx”尚未安装。 您可以使用以下命令安装:
> sudo apt-get install fcitx-bin
二、安装fcitx
sudo apt-get install fcitx-bin
相关的依赖库和框架都会自动安装上。
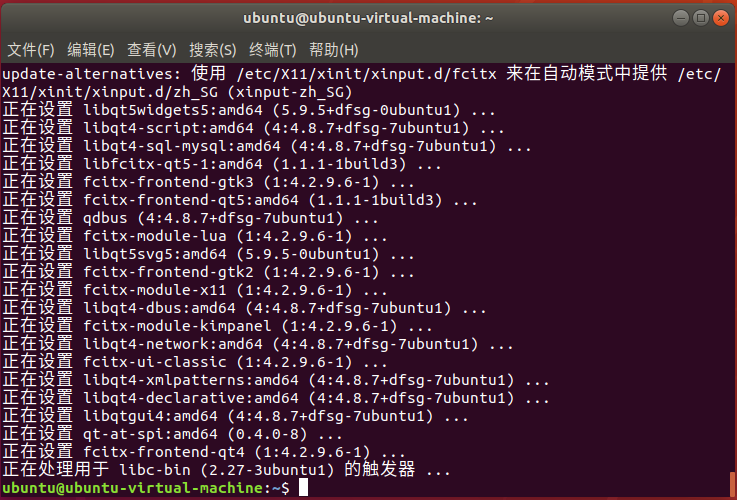
sudo apt-get install fcitx-table
安装输入法
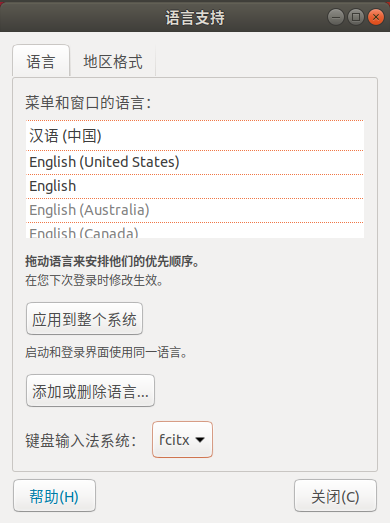
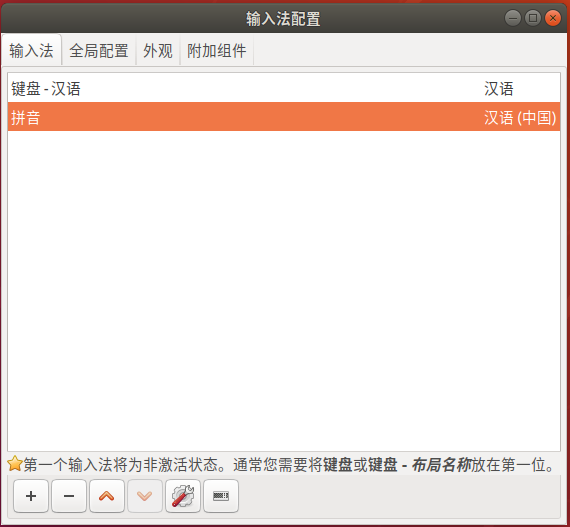
三、配置fcitx
默认iBus(非常难用),前面我们说过了,安装完fcixt后你尽可以如意地在 键盘输入方式系统 处把它替换为fcitx(如下图)。然后重启Ubuntu。
四、选择需要的输入法
点击Ubuntu右上角顶栏的小键盘图标中打开,配置,如下图:
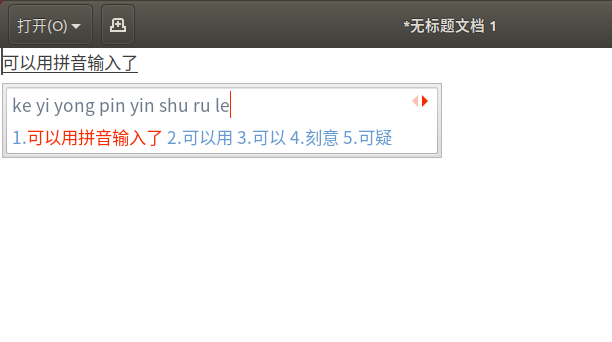
配置之后,就可以使用拼音输入了。
五、安装搜狗拼音
访问搜狗输入法For Linux
https://pinyin.sogou.com/linux/?r=pinyin
点击立即下载64bit,下载安装文件。
下载后,双击下载的文件。
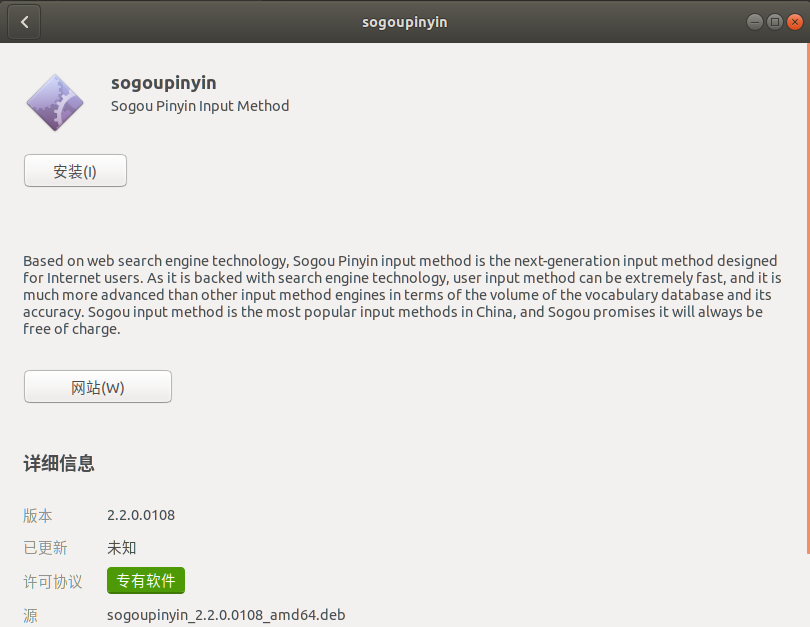
点击安装,输入密码,就可以安装了。安装完成重启Ubuntu。
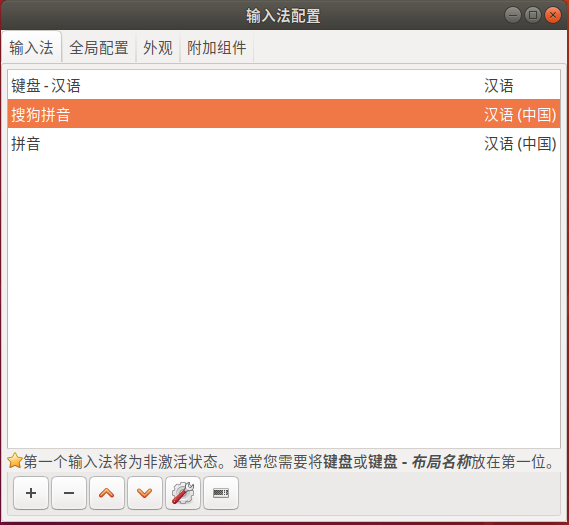
重启后,点击右上角小键盘-设置,调整一下输入法顺序。熟悉的输入感觉就来了。
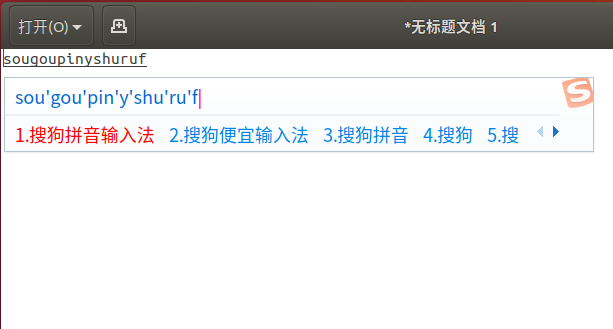
更改设置,点击输入操作条上的扳手按钮,可以设置皮肤,设置熟悉的习惯,还可以登录个人中心,同步个人词库。
这个canScrollVertically方法有两个坑
/**
* Check if this view can be scrolled vertically in a certain direction.
*
* @param direction Negative to check scrolling up, positive to check scrolling down.
* @return true if this view can be scrolled in the specified direction, false otherwise.
*/
public boolean canScrollVertically(int direction) {
final int offset = computeVerticalScrollOffset();
final int range = computeVerticalScrollRange() - computeVerticalScrollExtent();
if (range == 0) return false;
if (direction < 0) {
return offset > 0;
} else {
return offset < range - 1;
}
}
第一个坑:
注释的翻译是这样的:
检查此视图是否可以在某个方向上垂直滚动,
@param direction负值检查向上滚动,正向检查向下滚动。
@return如果此视图可以在指定方向滚动,则为true,否则为false
然而实际上,我把传入的direction设为负值,才是判断手指能否向下滑动,正值是判断手指能否向上滑动。不知道是不是作者对这个“滚动”的对象或者坐标系跟我理解的不同,总之,在我看来,这个注释和代码效果是完全相反的。
第二个坑,当recyclerview第一项是空布局的时候,包括本身是gone,高度是0 等等情况,都会导致用canScrollVertically(-1)始终返回true。也就是滑到顶部,不能在继续滑动的时候,这个方法仍然认为还可以继续滑动。
简直是大坑!!!这么常用的代码有这种问题,还不在注释中说明!不一点点debug源码,根本找不到原因。
知道了原因后,解决起来就很简单了,在原有布局外面嵌套一层布局,加上minHeight="1px"属性即可。
<FrameLayout
xmlns:android="http://schemas.android.com/apk/res/android"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:minHeight="1px"
>
<ExampleView
android:id="@+id/example_view"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:orientation="vertical"
/>
</FrameLayout>
vim是我最喜欢的编辑器,也是Linux下第二强大的编辑器。 虽然emacs是公认的世界第一,我认为使用emacs并没有使用vi进行编辑来得高效。 如果是初学vi,运行一下vimtutor是个聪明的决定。 (如果你的系统环境不是中文,而你想使用中文的vimtutor,就运行vimtutor zh)
以下移动都是在normal模式下。
上面的操作都可以配合n使用,比如在正常模式(下面会讲到)下输入3h, 则光标向左移动3个字符。
使用标记可以快速移动。到达标记后,可以用Ctrl+o返回原来的位置。 Ctrl+o和Ctrl+i 很像浏览器上的 后退 和 前进 。
注意,类似cnw,dnw,ynw的形式同样可以写为ncw,ndw,nyw。
y, d, c, v都可以跟文本对象。
可以用grep或vimgrep查找一个模式都在哪些地方出现过,
其中:grep是调用外部的grep程序,而:vimgrep是vim自己的查找算法。
用法为: :vim[grep]/pattern/[g] [j] files
g的含义是如果一个模式在一行中多次出现,则这一行也在结果中多次出现。
j的含义是grep结束后,结果停在第j项,默认是停在第一项。
vimgrep前面可以加数字限定搜索结果的上限,如
:1vim/pattern/ % 只查找那个模式在本文件中的第一个出现。
其实vimgrep在读纯文本电子书时特别有用,可以生成导航的目录。
比如电子书中每一节的标题形式为:n. xxxx。你就可以这样:
:vim/^d{1,}./ %
然后用:cw或:copen查看结果,可以用C-w H把quickfix窗口移到左侧,
就更像个目录了。
还有一种比替换更灵活的方式,它是匹配到某个模式后执行某种命令,
语法为 :[range]g/pattern/command
例如 :%g/^ xyz/normal dd。
表示对于以一个空格和xyz开头的行执行normal模式下的dd命令。
关于range的规定为:
高级的查找替换就要用到正则表达式。
:help pattern得到更多帮助。
g ^g可以统计文档字符数,行数。 将光标放在最后一个字符上,用字符数减去行数可以粗略统计中文文档的字数。 以上对 Mac 或 Unix 的文件格式适用。 如果是 Windows 文件格式(即换行符有两个字节),字数的统计方法为: 字符数 - 行数 * 2。
我们可以一次打开多个文件,如
vi a.txt b.txt c.txt
如果支持鼠标,切换和调整子窗口的大小就简单了。
这里是 滇狐总结的比较高级的vi技巧。
让vim 正确处理文件格式和文件编码,有赖于 ~/.vimrc的正确配置
大致有三种文件格式:unix, dos, mac. 三种格式的区别主要在于回车键的编码:dos 下是回车加换行,unix 下只有 换行符,mac 下只有回车符。
下面的括号匹配对编程很实用的。
有时一个tag可能有多个匹配,如函数重载,一个函数名就会有多个匹配。 这种情况会先跳转到第一个匹配处。
tab键补齐
Gtags综合了ctags和cscope的功能。 使用Gtags之前,你需要安装GNU Gtags。 然后在工程目录运行 gtags 。
vim提供了:make来编译程序,默认调用的是make, 如果你当前目录下有makefile,简单地:make即可。
如果你没有make程序,你可以通过配置makeprg选项来更改make调用的程序。 如果你只有一个abc.Java文件,你可以这样设置:
set makeprg=javac\ abc.java
然后:make即可。如果程序有错,可以通过quickfix窗口查看错误。 不过如果要正确定位错误,需要设置好errorformat,让vim识别错误信息。 如:
:setl efm=%A%f:%l:\ %m,%-Z%p^,%-C%.%#
%f表示文件名,%l表示行号, %m表示错误信息,其它的还不能理解。 请参考 :help errorformat。
其实是quickfix插件提供的功能, 对编译调试程序非常有用 :)
快速修改窗口在make程序时非常有用,当make之后:
当弹出补全菜单后:
normal模式下按:进入命令行模式